My buddy (and favorite Chemicals Professional) Bennett reports he's interested in a fitness tracker. I've been using my Jawbone UP 24 for about four months now, so it's a good time to write about it.
First, some background: I got burned by being an early adopter in this area about a year and a half ago. I went through six different copies of the Jawbone UP, v. 1, which was truly a horrible device. Once the pain of that experience faded, I tried some other trackers -- the Larklife (which I think has been discontinued) and the Fitbit Flex (which I wrote about here). But I finally got an UP24 and have been very happy with it since. Most tech writers seem to favor the Fitbit Force (assuming it isn't giving you horrible skin rashes), but I think the UP24 is an under appreciated piece of tech. Here's why.
Aesthetics and comfort. Let's get this out of the way first: I think the UP24 is one of the best-looking fitness trackers out there. The orange ("persimmon") is what I have, and the black is also a solid choice. If you go with the standard UP (to save $50), there are other nice colors available. These things look more like bracelets or fashion accessories than connected devices. They're also comfortable, too -- this is something you're buying to wear, literally, 24 hours a day (hence the name) -- so you can't understate the importance of this issue. The only times the UP24 gets uncomfortable or weird is when I'm pulling my arm out from underneath a pillow in the middle of the night. It's super easy to put on, take off, and charge. (Bennett is a swimmer, though, and the device is not waterproof. Rather, it's described as "showerproof.")
Fitness tracking. Want to record a workout with your UP24? Press the band a few times and it goes into stopwatch mode. When you're done, press it again to turn it off. If your workout was a run, you're basically done. If you did something else that the UP24 can't sense (e.g., bike riding, cross training), you go into the app and tell it what you did. Distance, time, calories burned, and so on are all baked in, and you can edit the intensity of your workout to fine-tune what's reported. I mostly use my UP24 to measure running workouts, so the device especially excels. The pedometer is generally accurate at measuring distance assuming I'm running at my usual slow pace. If I try to speed up or slow down even further, the estimates can get off (but never by more than half a mile or so). The biggest downside of the UP24 is that there's no screen on it, though, so you have no idea how far you've run while you're running. This means that before a workout, I'll have to map out my route and try and recall it during the run to make sure I do the right distance.
Sleep tracking. One of the main reasons I got the UP24 was to track my sleep. This hasn't been as useful as I thought it would be (although you can view my own public sleep data by clicking here -- although it seems to have broken, and I don't know why). Jawbone released a new UP Coffee app in the interests of helping users discover correlations between their daily activity and sleep habits, but knowing what we know about statistics, this sort of stuff requires a whole lot of data to be collected before "insights" become accurate.
Interconnectivity. Honestly, this is what makes the Jawbone UP24 the winner for me. Jawbone has spent more effort than any other fitness tracker has to ensure interconnectivity and interoperability between different "internet of things" devices. Here's what I mean. When I wake up, the living room lights turn on. When I hop on my scale, the data is sent directly to the UP app. Everything is simultaneously copied to my Google Drive, too. I could set up even more triggers, thanks to IFTTT (no other tracker supports this, to my knowledge), to text me when I hit a step limit, send an e-mail or a tweet if I've had a lazy day, or write a blog post if I report that I'm sad. I find this reassuring because it means that when it becomes time to try a new fitness tracker, I can take my data with me (perhaps with a bit of wrangling). Considering that personal fitness tracking has the potential to be a lifelong hobby, an eye toward archival and longevity is huge.
App. I like the Jawbone app a lot, too. I'm not going to get into it here, though. One warning: These guys seem to build for the iPhone first.
The bottom line: The Jawbone UP24 is a comfortable, fashion conscious wristband that provides a (relatively) inexpensive way to start collecting personal data. I'm happy with mine and love taking it on runs, and am hugely grateful that the device connects to so many other devices and services that I love. When something comes out with more and more accurate sensors and a screen (like some of Samsung's new offerings, perhaps), it might be time to upgrade. But for now, I don't foresee taking this thing off for the rest of the year at least.
A lot of angst on the internet today: an article talking about ageism in Silicon Valley and other issues, and another talking about the traditional operations of so-called "revolutionary" media companies. I can't write about the topic as well as the professionals can, but what I can say, is: Enjoy the hype, the money, the drama while you still can, everyone. It's not going to last.
Young people today joke about daytime T.V. -- "Who watches this? What a ridiculous medium! All of it is so empty, so useless!" But every step these companies take brings them a little closer to daytime T.V. status. Eventually, humans will realize that the internet can generate an illusion of meaning that, when you look at it carefully, doesn't really mean all too much.
So I guess this message is to say: Those of you out there doing real, meaningful work, keep it up. Be genuine and do what you believe in. I might not know you, but I am proud of you for doing what you do.
I took an eight mile jog around Forest Park today while I was thinking about these issues. Technically, it's spring break here at Washington University, so I've been taking some time to enjoy the warmer weather and think about some other projects, etc. (e.g., Skulving -- more about him one of these days); it's been a nice opportunity to clear my mind.
Back to your regularly scheduled research notes soon!
In a Facebook comment Jason Finley suggested that I graph the logistic regression curves for each individual subject in order to identify outliers, etc., writing, "Thoughtful. Try also making a tiny plot for each subject and eyeballing the lot of them."
So I did that for 20 of the 64 subjects and here's what we get:
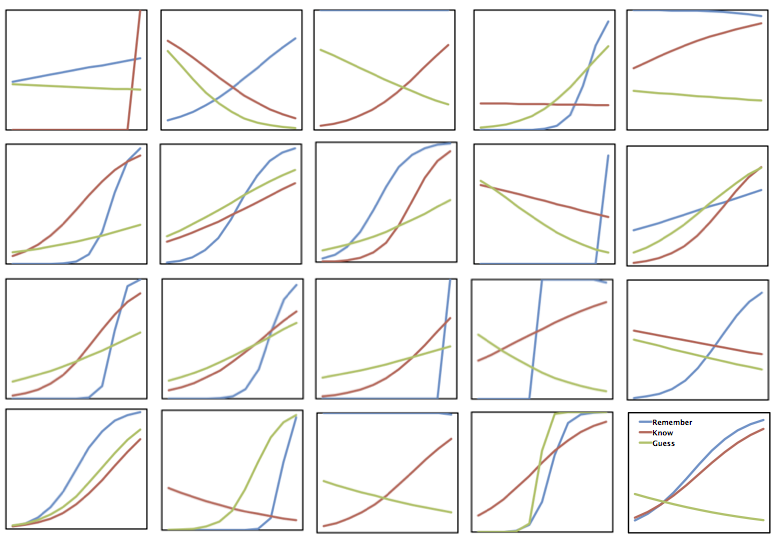
It's definitely a mess. Blue is remember, red is know, and green is guess (look here for a bit of background on the project). I'm staring at the plots trying to identify relationships and it isn't easy. Generally, the blue curves are highest to the right of the figures, suggesting that remember responses are more accurate than the other types when made at high confidence. And red is generally larger than green, too. But other than that, I'm at a loss.
The implication, then, is that there's a lot of variability within subjects in this procedure. My opinion is that an aggregated logistic regression equation, although valid for characterizing the overall relationship between confidence and accuracy as a function of remember, know, and guess, won't prove too useful on an individual level.
Here's an interesting finding from this morning's fiddling. I correlated performance on a task in the Memory Lab with performance on a task elsewhere (sorry, I'm being deliberately ambiguous for the moment). The correlation was significant and sizable at r = .93. Of course, any good researcher knows always plot your data, so here's how they look:
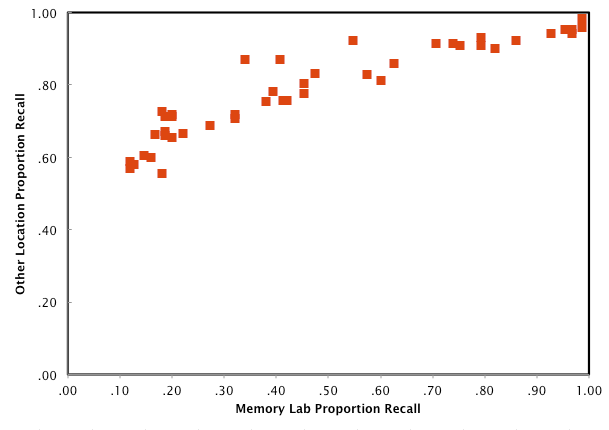
As you can see, the relationship looks somewhat logarithmic (or otherwise curvilinear). What causes that kind of relation? I'm pondering.
So in yesterday's notes I provided two logistic regression models that predict accuracy given confidence and remember/know/guess judgment. I noted that I was presenting results of a global regression, rather than the average of individualized subject-level regressions. Unfortunately, when we look at those, they aren't so pretty -- look if you dare:
Why is this happening, you ask? Well, it's mainly due to a few outlier subjects who have extraordinary remember and know coefficients. Subject 2 is -2142 log odds when he (or she) responds know, and Subject 19 is +1298 log odds when he responds remember. For reference, most of these other values are between -5 and 5.
So why do we have these outlier subjects? It comes down to strange variability in responding. For example, Subject 2, who had such weird data for know responses, shows some pretty unusual responses. Let's look at when he responds know:
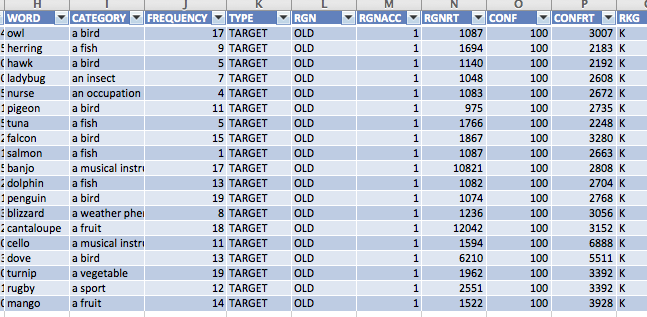
Do you notice what he's doing? He rates his confidence as 100 (on a 0-100 scale) every time he responds know. He's also right every time he responds know. (Someone who misunderstood the instructions?) Obviously, this is going to throw off the prediction equations.
So now the challenge becomes "come up with a rule to exclude outliers," if such a rule is needed. If you talk to open science types, they'll suggest that I should have come up with this rule before looking at the data. But this reveals an issue with such a strategy: This is the first time I've conducted this kind of research, and didn't know I would be bumping into this type of issue (let alone what a rule for dealing with outliers should be).
Of course, the solution is transparency -- I'll have to say this in my dissertation, and perhaps use the experience of this study to craft an outlier rule for use in the future Experiment 3.
In lab meeting today we watched a 60 Minutes by Morley Safer and Suzanne St. Pierre called "Lenell Geter's In Jail." You can watch it by clicking here. Our lab has been interested in applying principles of cognitive psychology to education for a while now, but recently we've been getting into the issue of eyewitness testimony and the relation between confidence and accuracy in memory.
This amazing segment, which runs 25 minutes or so, contains just about every classic mistake you can make when sentencing a man to prison for life. It's got a protagonist and some impressive villains. I want to share some of the details but it's really worth watching over dinner or something all the way to the end.
Actually, let's see if I can embed it here:
(Note: The embed doesn't seem to be working, sorry. Click the link up there.)
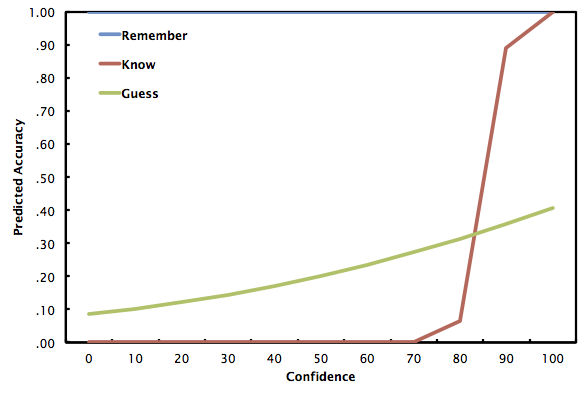
Now that I have my full complement of subjects (N = 64), I'm able to re-run logistic regression analyses and investigate the degree to which confidence is predictive of accuracy as a function of remember, know, or guess. I'll present two regression models. The first is just the effects of confidence on accuracy as a function of remember, know, or guess:
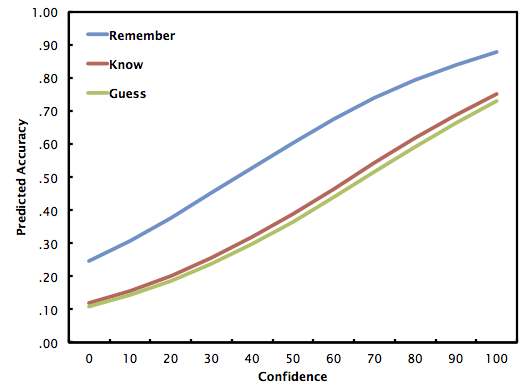
The regression equations for the figure above (Model 1) are:
For remember, log odds = -1.125 + .031c, where c is confidence (0-100)
For know, log odds = -1.999 + .031c
For guess, log odds = -2.104 + .031c
And here's what the prediction curves look like when we through in the interaction term (i.e., confidence x remember/know/guess). Let's call this Model 2.
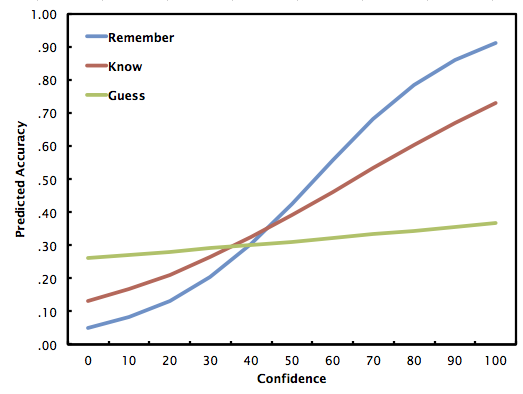
For remember, log odds = -2.946 + .053c
For know, log odds = -1.895 + .029c
For guess, log odds = -1.043 + .005c
Because logistic regression is not my strong suit, I am researching the best way to evaluate these global models. Right now I am not convinced that the model with the interaction term is doing that much better predicting accuracy. One thing I'm reading about is how we can use signal detection theory to compare models. Here's one way of taking a look:
Model 1: HR = .805, FAR = .402, d' = 1.11
Model 2: HR = .778, FAR = .337, d' = 1.19
So as you can see, not a huge improvement in discrimination (prediction) going from Model 1 to Model 2.
Now, this is the global analysis. I suppose the next step is getting the subject-level equations.
What can we draw from all of this? A possible observation, which we get from Model 2, is that there really perhaps is a difference in the predictiveness of confidence as a function of remember/know/guess. This is helpful because some of the analyses I presented last week suggested that there wasn't one. But what we show here is that one increase in a point of confidence is worth twice as much, in terms of log odds, when one is remembering as opposed to when one is knowing. And when people say they're guessing, they really are, regardless of confidence rating. They hover around what I think is chance (i.e., 33% accuracy). This is really neat.
Of course, these analyses are leaving out something rather important: "new" responses, because we never collect remember/know/guess judgments for "new" responses. We need to characterize those responses another day, but you could always turn to DeSoto and Roediger (2014) for one look at this issue.
Here's the data (and the formulae) used to make the figures above, if you're interested.
Like I mentioned a few days ago, Experiment 2 of my dissertation project -- Project 15 -- is finished with data collection. I've been slowly working my way through the data (have been busy with some other projects) and I like how things are looking.
Just to summarize, we have people come into the lab and ask them to learn 100 words from semantic categories. After a distractor task, we give them a test on 300 items: the 100 targets (words they studied), 100 related lures (unstudied words from studied categories), and 100 unrelated lures (unstudied words from unstudied categories). On this recognition test, one of the 300 words is displayed and subjects respond "old" or "new." Following this judgment, a 0-100 confidence rating is provided. Last, for words to which subjects responded "old," they make a remember/know/guess judgment. A remember judgment is provided when subjects can recollect the episode of the word's prior presentation. A know judgment is provided when subjects can't recollect the episode, but know that the word was presented. Last, subjects respond guess when they were just guessing the word is old.
Between-subjects confidence-accuracy correlations
The next thing to do is investigate the confidence-accuracy correlation as a function of remember, know, or guess. We can do that with scatterplots. Here we go:
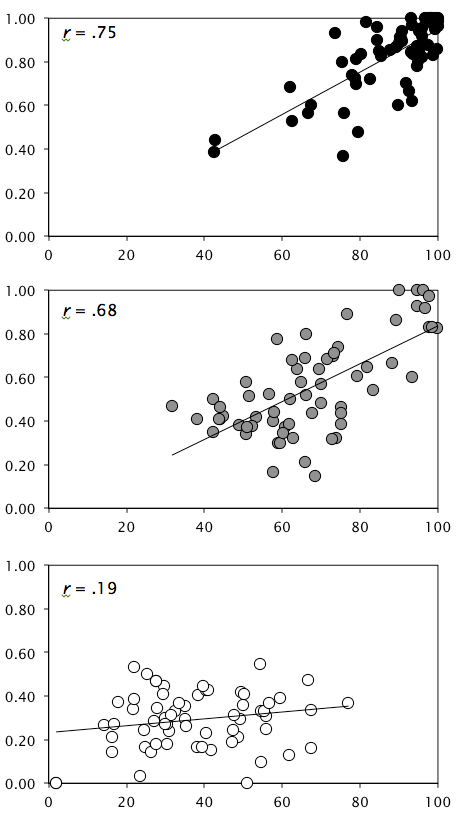
Using the terminology we used in DeSoto and Roediger (2014) , these scatterplots depict the between-subjects correlation, which indicates the degree to which confident subjects are more accurate. And what these data show is that confident subjects are similarly more accurate when responding remember or know, but there's not much relation in the guess responses.
Between-events confidence-accuracy correlations
And here's another one:
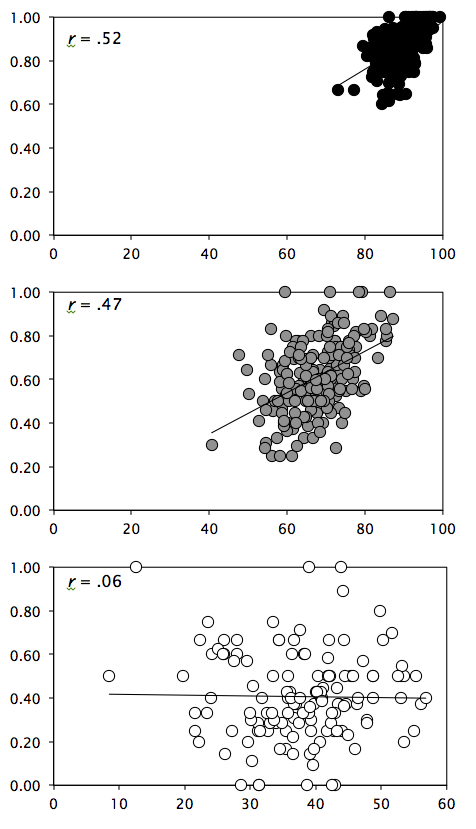
Again using prior terminology (i.e., DeSoto & Roediger, 2014), these scatterplots depict the between-events correlation, which indicates the degree to which items responded to with greater confidence are also responded to with greater accuracy. These data, like the prior one, show that increases in remembering are not substantially more predictive than increases in knowing. (But, like before, guesses are guesses.)
Dave Winer alerted me to the Knight News Challenge, a source of funding designed to strengthen the Internet for free expression and innovation. I've been thinking for a few hours now about ways a project done with Fargo might foster expression and innovation.
One of the big strengths of Fargo, in my opinion, is that it enables quick entry of organized information that can be published in an open way (i.e., via OPML and HTML). This makes it a powerful tool for scientists. Behavioral researchers like myself spend a great deal of time (1) writing and debugging experiment programs and software, (2) conducting data analyses with different statistical programs (e.g., SPSS) and programming languages (e.g., R, Python), and (3) writing and disseminating the resulting findings. To do all of these steps well (and in an open, reproducible way), good documentation is a necessity. Fortunately, like I've said, Fargo enables good documentation.
So an initial idea is to build services that strengthen Fargo as a means for academic and research documentation. Right now I am visualizing this as a "Fargo for academics," but of course, Fargo is already for academics (and programmers, poets, etc.; everybody else), so when I say "Fargo for academics," I mean that in an abstract way.
One tangible link/possibility: I have become an interested follower of the Center for Open Science (COS) stationed in Charlottesville, VA. The COS built and supports a tool called the Open Science Framework, which encourages open documentation of research and other academic collaborations. Right now the Open Science Framework uses a wiki-like system to record researcher notes. This system might be enhanced considerably by a connection to a tool like Fargo. It would be really neat to link up Fargo and the Open Science Framework for better research documentation, where you publish a note in Fargo and the OPML gets sucked up by the Open Science Framework.
So that's one fuzzy idea. Since I don't much know the folks at the COS (I do have a few connections, though), some more conversation there would be required. Since two of the six implementation objectives of COS involve strengthening infrastructure, though, I bet they'd be into it. The end goal would be to use Fargo to strengthen the internet for expression and innovation through open science -- something that'd be good for all of us.
A super neat Psychological Science paper we're reading for lab meeting next week. It makes a pretty basic claim, but one that's helpful to think about. Here it is: The likelihood we'll need a particular memory is a function of the frequency with which we've needed (or have experienced) the memory in the past. For example, I see my officemate Pooja pretty regularly, and interacting with her makes me think of her name. The chance that I'm going to need to remember her name over the next few days, then, is probably pretty high.
This has implications for forgetting. Specifically, as a function of prior exposure, it'll take me a long time to forget Pooja's name, too (in fact, that'll probably never happen, although I suppose there could be a slowdown in the rate at which I access her name when I'm 50 or something). Now on the other hand, the name of someone I've met just once or twice -- say, a sixth year PhD student when I entered graduate school -- was rarely used and likely quickly forgotten.
The overall idea here is that our memory system is adaptive (and almost Bayesian in nature): Prior experience is predictive of future demands. So when Becky says, "Andy, you never remember when I'm going out with my friends," the scientific response is, "There's very little cost associated with forgetting that information, so I don't remember it." But see, then I get in trouble, which increases the cost of forgetting. As a result, I'm a bit better at remembering when she's going out with friends.
Bottom line is -- a neat paper.