Now that I have my full complement of subjects (N = 64), I'm able to re-run logistic regression analyses and investigate the degree to which confidence is predictive of accuracy as a function of remember, know, or guess. I'll present two regression models. The first is just the effects of confidence on accuracy as a function of remember, know, or guess:
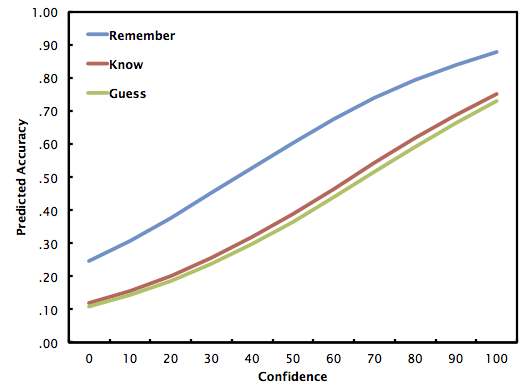
The regression equations for the figure above (Model 1) are:
For remember, log odds = -1.125 + .031c, where c is confidence (0-100)
For know, log odds = -1.999 + .031c
For guess, log odds = -2.104 + .031c
And here's what the prediction curves look like when we through in the interaction term (i.e., confidence x remember/know/guess). Let's call this Model 2.
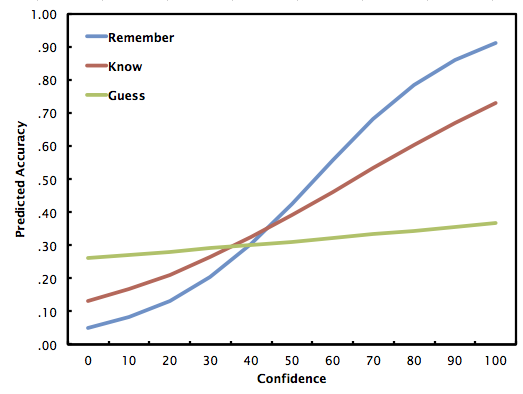
For remember, log odds = -2.946 + .053c
For know, log odds = -1.895 + .029c
For guess, log odds = -1.043 + .005c
Because logistic regression is not my strong suit, I am researching the best way to evaluate these global models. Right now I am not convinced that the model with the interaction term is doing that much better predicting accuracy. One thing I'm reading about is how we can use signal detection theory to compare models. Here's one way of taking a look:
Model 1: HR = .805, FAR = .402, d' = 1.11
Model 2: HR = .778, FAR = .337, d' = 1.19
So as you can see, not a huge improvement in discrimination (prediction) going from Model 1 to Model 2.
Now, this is the global analysis. I suppose the next step is getting the subject-level equations.
What can we draw from all of this? A possible observation, which we get from Model 2, is that there really perhaps is a difference in the predictiveness of confidence as a function of remember/know/guess. This is helpful because some of the analyses I presented last week suggested that there wasn't one. But what we show here is that one increase in a point of confidence is worth twice as much, in terms of log odds, when one is remembering as opposed to when one is knowing. And when people say they're guessing, they really are, regardless of confidence rating. They hover around what I think is chance (i.e., 33% accuracy). This is really neat.
Of course, these analyses are leaving out something rather important: "new" responses, because we never collect remember/know/guess judgments for "new" responses. We need to characterize those responses another day, but you could always turn to DeSoto and Roediger (2014) for one look at this issue.
Here's the data (and the formulae) used to make the figures above, if you're interested.