So in yesterday's notes I provided two logistic regression models that predict accuracy given confidence and remember/know/guess judgment. I noted that I was presenting results of a global regression, rather than the average of individualized subject-level regressions. Unfortunately, when we look at those, they aren't so pretty -- look if you dare:
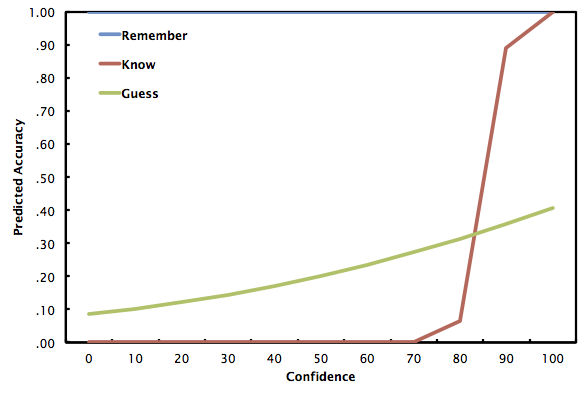
Why is this happening, you ask? Well, it's mainly due to a few outlier subjects who have extraordinary remember and know coefficients. Subject 2 is -2142 log odds when he (or she) responds know, and Subject 19 is +1298 log odds when he responds remember. For reference, most of these other values are between -5 and 5.
So why do we have these outlier subjects? It comes down to strange variability in responding. For example, Subject 2, who had such weird data for know responses, shows some pretty unusual responses. Let's look at when he responds know:
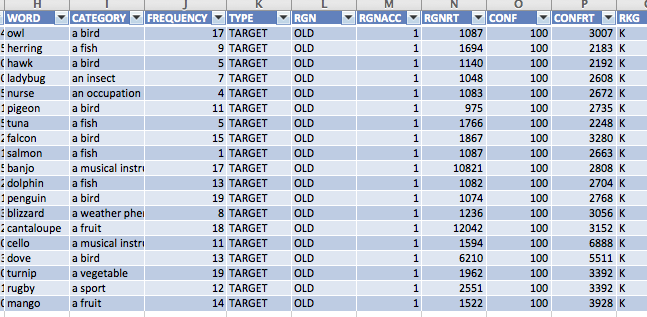
Do you notice what he's doing? He rates his confidence as 100 (on a 0-100 scale) every time he responds know. He's also right every time he responds know. (Someone who misunderstood the instructions?) Obviously, this is going to throw off the prediction equations.
So now the challenge becomes "come up with a rule to exclude outliers," if such a rule is needed. If you talk to open science types, they'll suggest that I should have come up with this rule before looking at the data. But this reveals an issue with such a strategy: This is the first time I've conducted this kind of research, and didn't know I would be bumping into this type of issue (let alone what a rule for dealing with outliers should be).
Of course, the solution is transparency -- I'll have to say this in my dissertation, and perhaps use the experience of this study to craft an outlier rule for use in the future Experiment 3.